Architectural Overview
Hyper-Scalable PAS utilizes nodes as servers to provide high availability and scale for your infrastructure solution. In Hyper-Scalable PAS, when one node fails, the system remains operational (provided you configured with multiple nodes as suggested). The following nodes make up the Hyper-Scalable PAS architecture:
-
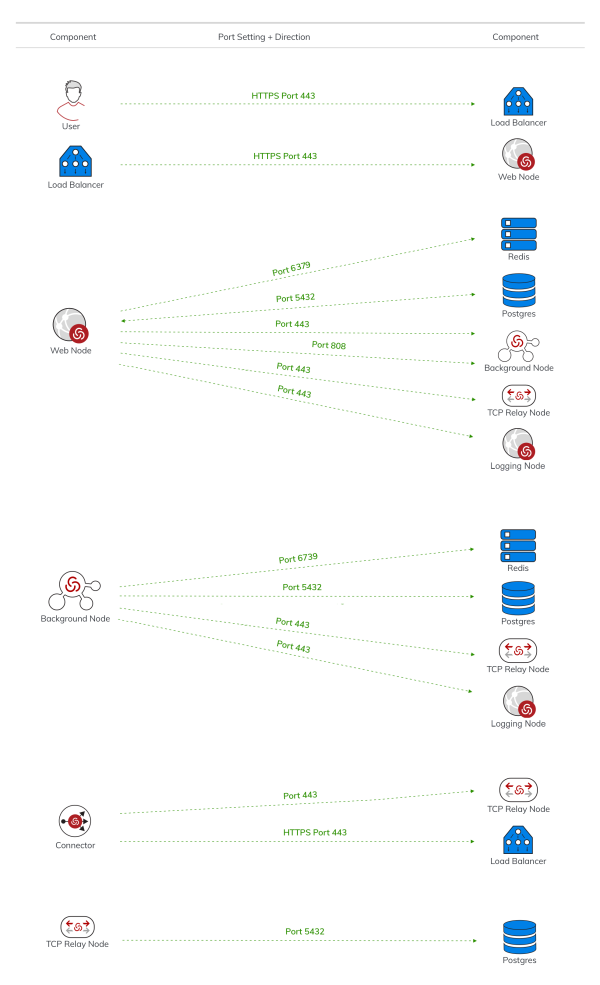
Web node—contains Hyper-Scalable PAS software and manages incoming web requests and provides REST endpoints (provides web API functionality). Webnodes communicate with Background nodes, TCP Relay nodes, Cache (Redis), and the Database (PostgreSQL) servers. All user-access to Hyper-Scalable PAS is through the Web nodes, which are reached at the host address through the load balancer. The Web nodes do not typically perform long-running or scheduled tasks; their job is to respond quickly to user requests. Only active Web nodes, those with the current active Deployment ID, respond to requests, and therefore only Web nodes receive traffic from the load balancer. You can add more Web nodes to scale up your architecture.
-
Background node—contains Hyper-Scalable PAS software and manages background jobs such as regularly rotating passwords, re-syncing with the DomainController and running reports. Background nodes communicate with Web nodes, Cache (Redis), and the Database (PostgreSQL) servers. The Jobs dashboard(/jobs) provides a view of the Background node workload. You can add moreBackground nodes to scale up your architecture if you notice delays or jobs are queued for extended periods of time.
-
TCP Relay node (Relay and Logging)—Relay and Logging TCP Relay nodes contain Hyper-Scalable PAS software and bridge between other technologies such asActive Directory, RDP hosts, log aggregation, and the Hyper-Scalable PAS deployment. Although a separate Logging node is not mandatory, IBM Security suggests you deploy a separate Logging node.
- The Relay node allows the Privileged Access Service to communicate with the Connector. Connectors are used to enable Active Directory integration, RDP access, and other integrations with the infrastructure. All TCP Relay nodes receive requests to forward data from Web nodes and/or Background nodes. If a request is Connector-bound (instead of, logging), it is forwarded along the Connector-initiated pipe.
- The Logging node centralizes the logs onto a single system for easier diagnostics, as well as allowing the logs to be watched on the Management node. The command
Centrify-Pas-WatchLogs.ps1will not work without a logging node.
-
Management node— scripts are executed from the Management node to manage the cluster. The Management node is not part of the cluster itself, however It does need to be able to reach Web, Background and TCP Relay nodes and have full database access. While the management node needs full database access, it doesn’t directly communicate with any other nodes beyond the initial installation.
Each deployed node (Web, Background, and TCP Relay) has an InstanceID or NodeID that is used to identify that specific server in the Hyper-Scalable PAS cluster.
-
Database (PostgreSQL) server—external database that is only used for Hyper-Scalable PAS. The database (PostgreSQL) never originates requests; it only receives and answers requests.
-
Cache (Redis) server—caches repeat operations to improve database performance. The cache (Redis) never originates requests; it only receives and answers requests.
-
Load balancer—load balances traffic to multiple servers (for Web node and connector traffic). The load balancer must have a static IP address, with an appropriate entry connecting the name (URI) to the address in the DNS.
Network topology
The following shows the port requirements and direction for Hyper-Scalable PAS.